Что такое EVPN/VXLAN

В этой статье я расскажу — что такое EVPN/VXLAN и почему особенности этой технологии кажутся мне привлекательными для применения в ЦОД. Я не буду глубоко погружать вас в технические детали, а остановлюсь на них лишь в той мере, в которой это необходимо для знакомства с технологией. Почти все чего я буду касаться в этой статье так или иначе связанно с передачей трафика второго уровня OSI между устройствами в одном широковещательном домене. Есть множество задач прикладного характера, которые можно комфортно решить, имея такую возможность, одним из наиболее знакомых примеров такой задачи является миграция виртуальных машин в рамках одного или нескольких ЦОД. И если некоторое время назад разговор об этом неминуемо поворачивал в плоскость обсуждения проблем и неудобств общего широковещательного домена, сейчас, напротив, мы можем размышлять о решении этой задачи с точки зрения новых возможностей, перспектив и удобства.
Индустрия ЦОД характеризуется особенно высокой плотностью приложений, помноженной на ожидания потребителей, поэтому выбор архитектуры сетевой подсистемы является особенно важным. В беседах с заказчиками я обычно предлагаю трансформировать абстрактные величины характеристик функционирования сетевой подсистемы в область оценки влияния этих величин на бизнес задачи клиента и рисков возникновения того или иного события в жизненном цикле сетевой подсистемы. Это дает возможность рассмотреть знакомые величины с точки зрения предметной области заказчика, например, абстрактные 2 секунды сброса пакетов во время перестроения топологии, свитчовера или регламентных действий могут превратиться во вполне осязаемые 2.5 Гигабайта потерянных данных на каждом 10G порту. Нынешние тенденции уплотнения сервисов и повышения скорости портов актуализируют проблему надежности и стабильности, так как цена секунды простоя в пересчете на бизнес метрики кратно увеличивается в соответствии со ступеньками скоростей 1G-10G-25G-40G-100G.
В традиционной сети второго уровня OSI с множественными путями между коммутаторами мы обязаны использовать STP, MLAG или стекирование. Я кратко опишу индивидуальные особенности этих технологий чтобы стали понятны предпосылки появления новой архитектуры сетевой подсистемы ЦОД. STP сокращает эффективную пропускную способность, просто отключая порты. К этой технологии также есть большие претензии с точки зрения времени сходимости. У STP есть другие минусы, многие знают о них не хуже меня, поэтому любой из реализаций STP ни под каким предлогом не место в ЦОД.
С точки зрения рассмотрения перспектив развития к MLAG, в качестве ядра ЦОД, возникает много вопросов. Нужно четко понимать тот факт, что топология MLAG по определению не может содержать более двух коммутаторов агрегации, и, по-хорошему, требует наличия горизонтальной связи удвоенной емкости между ними. В связи с отсутствием возможности сегментирования и управления трафиком внутри и между шасси применение этой технологии в территориально распределенной среде может быть затруднительным. А определение ресурсов, необходимых для предотвращения события «Dual Master», с помощью предметного анализа сценариев отказа, может чрезвычайно перегрузить решение с точки зрения аппаратной составляющей. Несмотря на то, что коммутаторы агрегации MLAG продолжают функционировать раздельно, они чрезвычайно тесно связаны с точки зрения физической топологии, поэтому пристальное рассмотрение деталей функционирования иногда делает технологию не такой уж привлекательной.
Эксплуатация стека в качестве ядра ЦОД сопряжено с рисками нахождения всех яиц в одной корзине, так как, несмотря на привлекательность и кажущуюся простоту общего Control Plane per Stack, ошибки в программном обеспечении имеют место быть, и вы не застрахованы от их появления именно в вашем случае. Хуже то, что ошибка обычно не может быть локализована в Fault Domain приемлемого размера, стек это не только один большой коммутатор, но и один большой Fault Domain. Тот факт, что возможности стека зачастую ограничены самым слабым компонентом, так как по определению многие таблицы коммутационных чипов должны быть идентичными на всех устройствах, тоже не стоит упускать из вида. К стеку, функционирующему, в распределенной среде возникают тот же набор вопросов отказоустойчивости, которые кратко описаны выше для случая применения MLAG. Кольцевая топология, которой ограничиваются некоторые производители стекируемых коммутаторов, характеризуется потенциально более перегруженными стек портами ближе к границе. В зависимости от профиля вашего трафика это может оказаться проблемой, на которую так же нужно обратить внимание с точки зрения расчета фактической переподписки.
Термин VXLAN обозначает виртуальную расширяемую локальную сеть, и вы можете найти много сходств и думать о VXLAN так же как о VLAN. Но различие в том, что VXLAN это туннель (одностороннее виртуальное соединение между двумя коммутаторами), если говорить более точно это инкапсуляция Ethernet over UDP.

Привычная передача трафика второго уровня между хостами происходит на основе информации о расположении MAC адресов, таблицу которых хранят промежуточные коммутаторы, они обновляют свои знания о сети с помощью механизма слепого обучение по факту прохождения трафика. В мире VXLAN, многое меняется, так, например, для передачи трафика второго уровня промежуточные коммутаторы вовсе не обязаны работать на втором уровне в рамках одного широковещательного домена. Туннелирование Ethernet трафика позволяет транзитным коммутаторам абстрагироваться от понятия MAC адресов, и выполнять свои функции в рамках IP фабрики свободной топологии по правилам маршрутизации. Каждый коммутаторы в ЦОД работают абсолютно независимо от своих соседей, это напоминает распределенную работу сети Интернет, так как регламентные работы на каждом устройстве имеют строго локальный характер. Гибкая физическая топология позволяет четко подстраиваться под профиль трафика в конкретно взятом ЦОД, а свободный выбор типов и количества соединительных портов позволяет строить сети с заданным уровнем переподписки, вплоть до полностью неблокируемых.
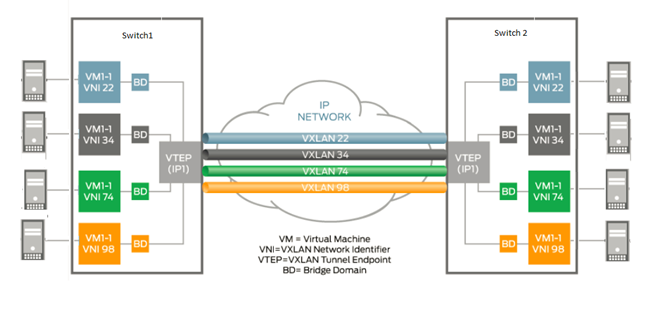
Когда трафик от хоста А к хосту B попадает на пограничный коммутатор в виде кадра второго уровня, этот кадр упаковывается внутрь IP пакета и отправляется по IP сети к пограничному коммутатору другой стороны чтобы там произошла процедура распаковки. Началом эпохи разделение компонентов сети на транспортную и сервисную составляющие принято считать внедрение BGP Free Core на базе технологий MPLS в сетях операторов связи. Применительно к ЦОД эта тенденция материализовалась относительно недавно в качестве метода решения задач масштабируемости и упрощения эксплуатации, компоненты такой архитектуры обычно называют Underlay — транспортная сеть, и Overlay — сервисная или виртуальная. Более детально архитектура Network Virtualization Overlays описана в документах [1, 2]. Разделение функций сетевой подсистемы ЦОД, позволяет конфигурировать сервисы отдельно от конфигурации транспортной составляющей. Вы больше не обязаны определять Vlan на каждом транзитном коммутаторе по цепочке, вместо этого вы описываете Overlay сети путем настройки сервиса только там, где он фактически предоставляется, при этом обмен трафиком Overlay сетей в рамках сервиса осуществляется через туннели на базе Underlay сети. С другой стороны, вполне ожидаемым является тот факт, что проведение таких активностей на Underlay сети как изменение физической топологии, добавление/удаление коммутаторов или каналов связи, будет иметь нулевое влияние на конфигурацию сервисной составляющей. Ядро или транспортная составляющая сети ЦОД при этом свободны от обработки и хранения состояний сервисов, табличное пространство коммутационных чипов коммутаторов ядра используется исключительно в рамках задачи построения связности, передачи трафика и обеспечения быстрой сходимости, а информация о состояниях сервисной составляющей присутствует только на границе сети ЦОД.
Примерно в это же время крупные операторы связи и ведущие производители сетевого оборудования заканчивали разработку нового стандарта передачи трафика второго уровня на базе MPLS сетей. К технологии VPLS накопилась критическая масса неудовлетворенных требований в таких задачах как:
- обеспечение балансировки потоков при подключении клиента к двум PE.
- обеспечение балансировки потоков между PE.
- обеспечение резервирования в территориально распределенных конфигурациях.
- обеспечение быстрой сходимости.
- оптимизация доставки трафика.
- снижение уровня BUM трафика.
Эти требования нашли реализацию в новом стандарте под названием Ethernet VPN, с полным текстом предложений можно ознакомится в [3].
Чуть позже было предложено адаптировать операторскую модель EVPN на базе MPLS к применению в IP сетях ЦОДов. Для этого потребовалось согласовать некоторые процедуры стандарта с особенностями VXLAN инкапсуляции и парадигме hop-by-hop маршрутизации, а также несколько дополнить таксономию типов PE устройств — MPLS реализация подразумевает поддержку функций маршрутизации виртуальных сетей всеми PE, а в VXLAN реализации появляется упрощенный тип PE только для коммутации внутри виртуальной сети [4].
VXLAN и EVPN являются стандартами [5, 6] и вы можете надеяться на согласованную работу в мультивендорной сети [7]. Первый стандарт интересен тем что описывает детали инкапсуляции Ethernet трафика, он относится к тем вещам, которые мы видим «на проводе». Второй стандарт намного более объемный, там описаны правила обмена информацией о MAC адресах как об IP префиксах и предложена модель поддержки множественных тенантов или сервисов на базе общей сети. Для всего этого не стали придумывать отдельный протокол, авторы решили дополнить BGP новыми сущностями. Итак, если говорить просто — VXLAN это инкапсуляция на проводе или data-plane, EVPN — это набор правил, руководствуясь которыми коммутаторы передают трафик второго уровня поверх IP сети, т. е. control-plane.
Имея в своем распоряжении только VLAN теги, вы можете оперировать количеством сервисов или сегментов ограниченным сверху 12-ти битным числом, т. е. 4096. В VXLAN для идентификации сегментов отводится уже 24 бита, т. е. предельное количество экземпляров VNI (это аналог VLAN тега) равно 16-ти миллионам. Не думайте о первом числе как о чем-то недостижимом, а о втором как о бесполезно большом, в сети ЦОД с множественными сервисами оценка величины требуемых сегментов вполне может приблизиться к верхнему пределу количества VLAN. Сравнение с точки зрения этой количественной характеристики напоминает IPv4 против IPv6.
EVPN/VXLAN поддерживает передачу трафика второго уровня по множественным путям (ECMP передача). Если вспомнить что VXLAN это туннель, станет понятно, что это свойство наследуется совершенно естественным образом. Достаточно указать точку назначения туннеля в IP заголовке внешнего пакета, и у транзитных коммутаторов появляется возможность утилизировать потоками трафика все возможные пути. Инкапсуляция VXLAN специально разработана таким образом чтобы передача потока с соблюдением последовательности пакетов не требовала серьезной инспекция транзитного пакета. Для этой цели используется заголовок транспортного уровня, полем повышения энтропии трафика и идентификатором потока служит номер UDP порта. Заполнение этого поля выполняется на пограничных коммутаторах, так чтобы транзитным коммутаторам не приходилось глубоко заглядывать в содержимое пакета, что снижает требования к их коммутационным чипам. Это означает что вы можете строить высокопроизводительные IP фабрики используя коммутаторы общего назначения.
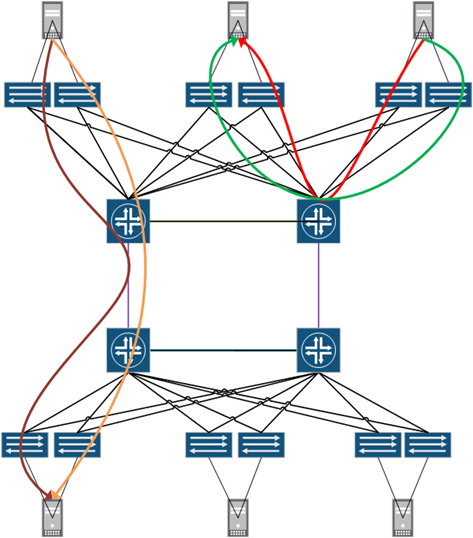
Я уже писал, как использование Overlay сетей влияет на масштабируемость ядра сетевой подсистемы ЦОД, давайте рассмотрим еще один аспект этого понятия — снижение уровня широковещательного трафика. Этот вопрос в функционале EVPN рождает больше всего недопонимания, но на самом деле все просто. Коммутаторы EVPN используют программный метод обучения MAC адресов на базе обмена BGP сообщениями, после появления нового MAC адреса на порту доступа выполняется синхронизация таблиц коммутации по всей сети. К моменту начала передачи трафика включившегося сервера, таблицы коммутации уже содержат актуальную информацию, поэтому у удаленной стороны нет необходимости реплицировать кадр с unknown unicast адресом назначения на все порты доступа ЦОД. Это существенное отличие от классического метода «слепого» наполнения таблиц по факту поступления трафика, не только оптимизирует полосу на каналах связи и портах доступа ЦОД, но и снижает накладные расходы на обработку фреймов второго уровня серверами, которые не должны являться их получателями.
Программное обучение MAC адресам делает их более мобильными, в стандарте предусмотрены, лишенные недостатков широковещательной репликации, процедуры подготовки таблиц коммутации для случая перемещения MAC адреса с одного порта доступа на другой, как это обычно происходит в момент горячей миграции виртуальной машины.
Вопросы времени сходимости и реакции на изменение топологии необходимо рассматривать в компонентах Overlay и Underlay по отдельности. Что касается Underlay сети, старайтесь придерживаться общепринятых практик построения маршрутизируемых сетей, применительно к IP фабрике они выражаются несколькими простыми рекомендациями:
- используйте BFD чтобы транзитные коммутаторы могли детектировать аварийную ситуацию менее чем за секунду;
- старайтесь придерживаться симметричных топологий с параллельными путями, это позволит коммутатору на границе аварии выполнять роль точки восстановления трафика еще до того момента как информация об аварии достигнет источника трафика;
- выбирайте топологии, которые допускают альтернативные маршруты с предустановленными в коммутационный чип путями без риска появления micro loops.
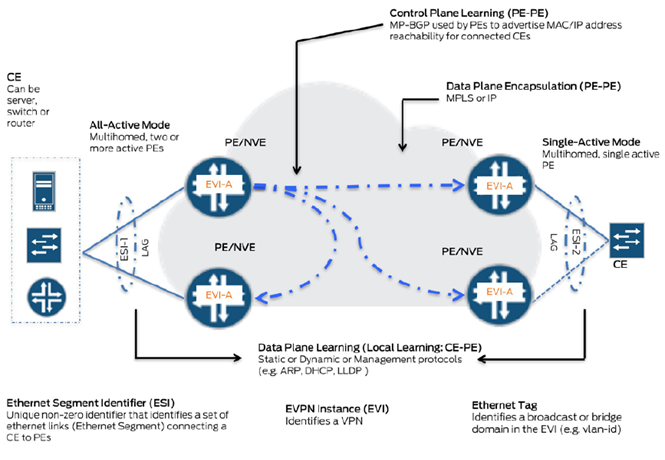
Больший интерес для темы данной статьи представляет описание применения программной модели обучения MAC адресов в Overlay сети для сценария включения или отключения порта доступа. Коммутаторы доступа, к которым подключены сервера, помимо адресной MAC информации, обмениваются топологической. Набор портов доступа на двух или более коммутаторах, которые подключены к одному серверу, относят к уникальному в рамках широковещательного домена номеру Ethernet сегмента (Ethernet Segment Identifier- ESI). Это дает возможность удаленным коммутаторам сопоставлять MAC адрес назначения с номером Ethernet сегмента и выбирать для передачи трафика коммутаторы, которые объявили себя подключенными к данному сегменту, даже если они явно не передавали информацию о MAC адресах на порту доступа.
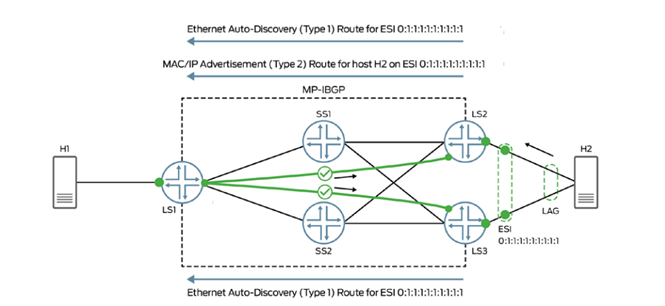
При отказе или отключении порта, коммутатор сигнализирует об аварии используя сообщение отключения от Ethernet сегмента, таким образом удаленные коммутаторы могут обновить таблицу коммутации, не дожидаясь генерации и обработки набора сообщений об отключении всех MAC адресов по отдельности.
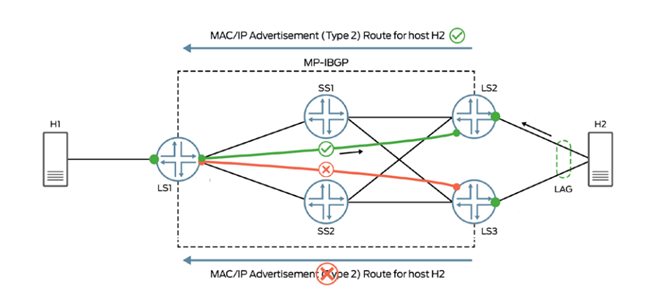
Предыдущие текст по большей части касался передачи трафика второго уровня OSI, это далеко не единственная область применения EVPN, сейчас я расскажу почему об этой технологии говорят, как о методе интеграции маршрутизации и коммутации. Давайте подумаем, что мешает присутствию двух или более маршрутизаторов в одном сегменте сети второго уровня. Ответов может быть много, но один из них звучит примерно так — потому-то на втором уровне OSI нет возможности передавать трафик по множественным путям. Коммутатору нужно точно знать в какой порт отправлять трафик к MAC адресу маршрутизатора по умолчанию, так как этот адрес в классической Ethernet сети не может быть активным на разных портах одновременно. Но, как мы увидели раньше, разработчики EVPN реализовали Active-Active передачу трафика на базе программного метода распространения MAC информации, поэтому два или более двух коммутаторов могут объявить своим EVPN соседям о локальном присутствии MAC адреса маршрутизатора по умолчанию в рамках VXLAN сети. Маршрутизация между сетями может осуществляться в Active-Active режиме на множестве коммутаторов, объявивших себя маршрутизаторами по умолчанию. Эти устройства ведут себя как распределенный маршрутизатор, каждая часть которого имеет один и тот же IP и MAC адреса или Anycast Gateway, т.е. проблема превращается в преимущество. EVPN предусматривает механизмы обмена не только MAC, но и IP информацией, поэтому табличные данные и поведение распределенного маршрутизатора будет идентично на всех его компонентах.
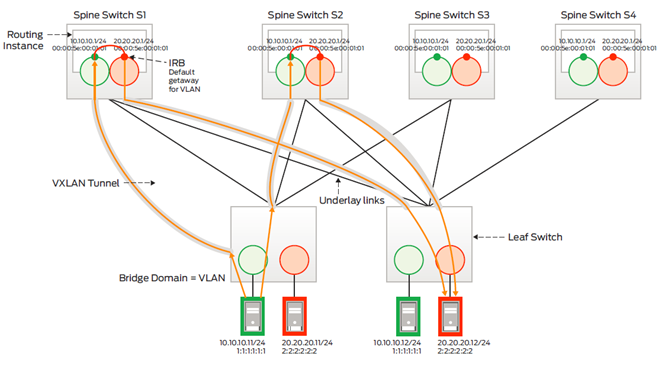
Применительно к симметричной топологии ЦОД маршрутизацию обычно реализуют в одном из четырех вариантах:
- на всех Spine коммутаторах;
- на всех Leaf коммутаторах;
- на выделенных Leaf коммутаторах;
- на маршрутизаторе вне Overlay домена;
Первый вариант характеризуется довольно простой реализацией механизмов инспекции активности приложений (Security Insertion) и организации цепочек обработки (Service Chaining) [8], так как сервисный блок сетевой подсистемы ЦОД взаимодействует с относительно не большим количеством Spine коммутаторов, где и выполняются политики доставки трафика.
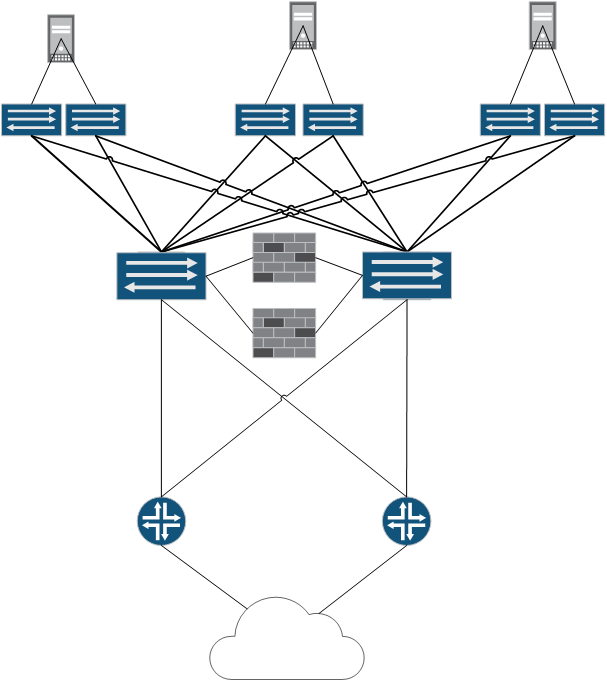
С другой стороны, маршрутизация на Leaf уровне выглядит более привлекательно с точки зрения общего времени передачи и утилизации портов, но симметричное подключение таких блоков сетевой подсистемы ЦОД как сервисный и пограничный, может вызвать неоправданные сложности. Поэтому часто выделяют так называемую сервисную стойку или стойки, Leaf коммутаторы в которых целиком и полностью работают мостиком между Overlay сетью и остальными блоками сетевой подсистемы ЦОД. При этому значительно снижаются ожидания к коммутаторам Spine уровня, по сути от них требуется только передача IP трафика, но на практике обычно эти коммутаторы так же выполняют функцию отражателей маршрутов BGP-RR.
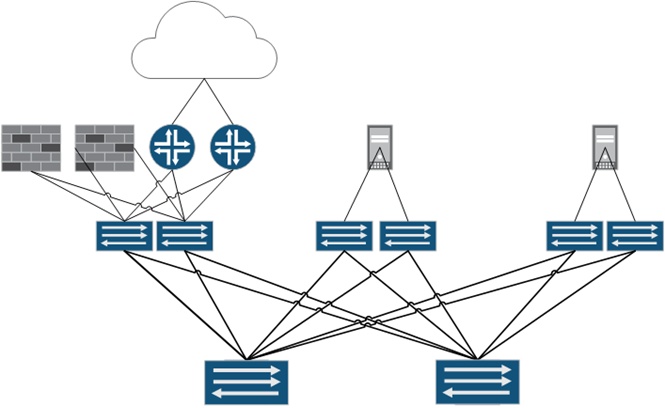
Технически говоря, трафик между VXLAN сетями можно маршрутизировать и вне Overlay домена, классический IP маршрутизатор вполне может быть подключен к порту доступа EVPN/VXLAN сети в качестве клиента. Но этот метод лишен таких полезных качеств как Active-Active передача к Anycast-Gateway и не удовлетворяет требованиям резервирования, поэтому на практике используется только как промежуточный этап, в качестве метода плавной миграции транспортной компоненты сети ЦОД с Ethernet к EVPN/VXLAN.
- [1] RFC7364 «Problem Statement: Overlays for Network Virtualization»
- [2] RFC7365 «Framework for Data Center (DC) Network Virtualization»
- [3] RFC7209 «Requirements for Ethernet VPN (EVPN)»
- [4] draft-ietf-bess-evpn-overlay «A Network Virtualization Overlay Solution using EVPN»
- [5] RFC7348 «Virtual eXtensible Local Area Network (VXLAN): A Frameworkfor Overlaying Virtualized Layer 2 Networks over Layer 3 Networks»
- [6] RFC7432 «BGP MPLS-Based Ethernet VPN»
- [7] EANTC «Multi-Vendor Interoperability Test», 2017;
- [8] draft-ietf-bess-service-chaining-03 «Service Chaining using Virtual Networks with BGP VPNs»