Из серии разговоров с коллегами или крупицы опыта: дизайн DC Edge

Вчера общался со своим старым приятелем, он рассказал о завершении проекта модернизации большого ЦОД — сетевой дизайн с чистого листа, Leaf/Spine, TOR, новое оборудование, отказоустойчивость, все красиво и свежо. Мы знакомы еще с тех пор когда 40Gbit/s на слот казалось чем-то запредельным, собственно наши профессиональные дороги плотно сошлись на фоне изучения внутренней переподписки, архитектуры и особенностей передачи трафика в линейных картах одного известного производителя. Поэтому, когда приятель спросил: «А знаешь почему я тебе звоню?», я, нисколько не задумываясь, ответил — «Что, опять дропы?»
Получив утвердительный ответ, я попытался выяснить то что пытаются выяснить в такой ситуации — матрицу и профиль трафика, модели коммутаторов, отношение емкостей вверх/вниз, порядок количества активных серверов, типы портов и все такое прочее. Выносить подробности услышанного на всеобщее обозрение я не могу, однако, не лишним будет сказать, что коммутаторы, с которыми имеет дело мой приятель, построены на базе Trident-2 от Broadcom, а значит проблема, описанная ниже, в известной степени, не является уникальной для конкретного производителя. Заметка скорее не про внутреннюю архитектуру, а про внешний дизайн в целом. Итак, мне удалось выяснить, что нарекание вызывает пара Leaf коммутаторов, которые предназначены для подключения ЦОД к внешнему миру и сервисным устройствам.
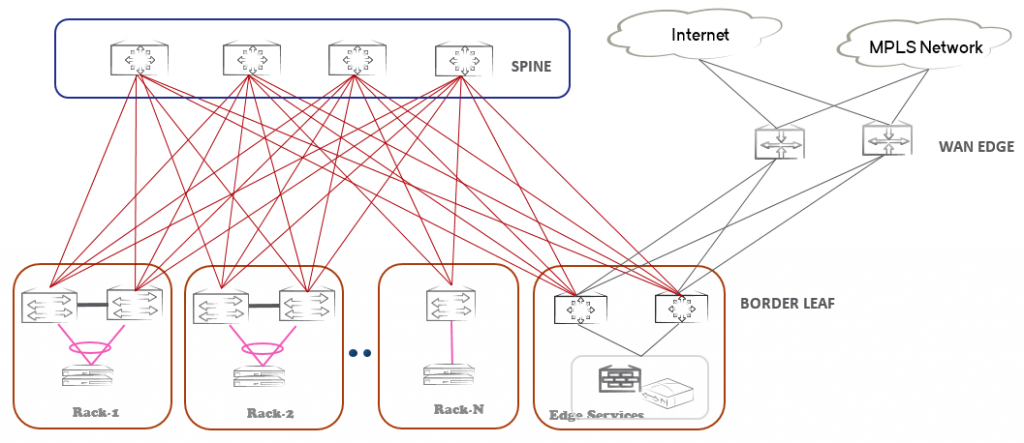
Оказалось, что, что на паре Border Leaf коммутаторов собраны «широкие» LAG-и в сторону вышестоящих маршрутизаторов WAN Edge. Трафик ЦОД обычно имеет асимметрию в отношении входящей и исходящей полосы, нас интересует направление Border Leaf — WAN, на котором наблюдаются дропы. С одной стороны, мы имеем несколько 40G портов до Leaf, с другой — LAG из 10G портов с еще большей емкостью. При этом средняя полоса не доходит даже до половины возможной. Я еще раз уточнил у приятеля, какими типами портов подключаются сервера, оказалось, что все TOR имеют 10G на портах доступа. Тогда я предложил подумать о этой сети, как о старом добром TDM — каждый порт в LAG до WAN можно представить одним тайм-слотом, предположим, что остальная фабрика полностью не блокируемая, т.е. как только некий сервер инициирует отправку потока, один из тайм-слотов утилизируется эксклюзивно под эти нужны. Сделав такое допущение, мы будет не далеки от истины, так как канальные скорости портов доступа и портов в LAG-ах до WAN совпадают, при этом сервер всегда «выбрасывает» данные в сеть на канальной скорости своей сетевой карты. Если речь идет о TCP протоколе, тайм-слот резервируется на время необходимое для передачи объема байт равному TCP окну. Каким бы «широким» не были LAG-и, количество серверов в ЦОД явно превышает число портов в нем, поэтому два (на самом деле больше) потока вполне могут оказаться в буферной памяти (мы вернулись от TDM к Ethernet сетям) ожидая отправки по одному и тому же порту.
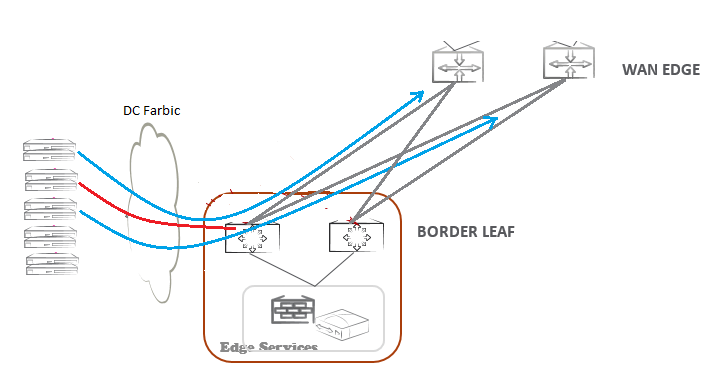
Правильно ли строить стыки с ЦОД с WAN на канальной скорости порта доступа? Такой подход может работать если объем буферной памяти коммутатора способен вместить Incast всплески трафика, с чипами Broadcom такой фокус зачастую не получается. 9-12Mb буферной памяти на SoC для 48-ми портов стандартного TOR коммутатора, позволяет сглаживать всплески c двух источников длительностью не более 9Mb/1250Mb/s = 0,0072s, где 1250 объем данных передаваемых на 10G порту каждую секунду. Число одновременных источников не равно числу серверов, и для каждого ЦОД требует своей оценки с учетом наблюдаемого трафика, но в любом случае оно больше двух. В данном случае TOR на чипе Broadcom «развернули» с точки зрения трафика и заставили заниматься совсем не привычным для него делом. Вместо того чтобы принять трафик с низкоскоростных и портов и отдать его по высокоскоростным, минимизируя потребление буферной памяти, чип вынужден делать все наоборот.
Давайте вернемся к дизайну чтобы выработать решения проблемы, навскидку их несколько:
- Заменить коммутаторы Border Leaf с Broadcom на коммутаторы с глубокой буферной памятью (Deep Buffers). У многих производителей есть модели, построенные на чипах собственной разработки, специализированные для такого рода применений.
- Повысить канальную скорость портов LAG до WAN так, чтобы эта скорость превышала канальную скорость портов доступа.
- Перейти на Flex Ethernet, когда эта технология придет в ЦОД.
Как видите, первые два варианты требуют обновления аппаратной составляющей, в запущенном проекте такое обычно не приветствуется, а третий вариант и вовсе экзотичный. К тому-же каждое внедрение требует проработки. А эту проблему нужно было решить здесь и сейчас, поэтому я предложил пойти по Scale Out пути. Чего много в ЦОД? TOR коммутаторов конечно — есть набор ЗИП, есть для расширения. Добавление четного количества Border Leaf и перераспределение портов LAG по ним, кратно снижает число конкурирующих потоков и перераспределяет их по появившейся буферной памяти. В качестве быстрого решения проблемы, по-моему, не плохо, а к разговору по правильному пути номер один мы еще вернемся.